


Reference: Berry, M.J.A. and Linoff, G.S., Mastering Data Mining, Wiley: New York, 2000.
Two Styles of Data Mining
1. Directed Data Mining:
- Top-down approach
- Used when we know approximately what we are looking for or what we want to predict
- Predictive model uses experience to rank possible outcomes in the future by calculating a score for each outcome
- Model is seen as a black box because we care only about the predictions and not how it actually works
- Goal of building a predictive model is to apply knowledge gained in the past to the future
- Example problem: Which customers are likely to buy a specific type of car?
2. Undirected Data Mining:
- Bottom-up approach
- Finds patterns in the data and leaves it up to the user to determine whether or not these patterns are important
- We want to know how the model works and how it comes up with the answer
- Human interaction is necessary because only people can determine what significance, if any, the patterns have
- Often used during the data exploration steps
- Example: A person looks at a decision tree and possibly notices an interesting pattern.
- For directed data mining a decision tree could make predictions.
The Virtuous Cycle of Data Mining
Consists of four major business processes (success in data mining requires all four):
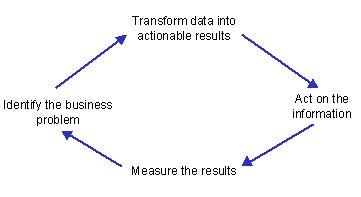
1. Identify the Business Problem
- Important that technical people understand what the real business needs are
- Do this by talking to domain experts: the people who understand the business
- Business people need to be kept informed of the development, so that they may make continuing contributions to the project and the focus remainson the business needs
- It is important to think outside the confines of domain experts' knowledge to understand the real problem
Business people's expertise allows you to answer the following questions:
- Is the data mining effort necessary? For example, if the purpose of a marketing campaign is to get every single possible responder, then it would be a waste of money to build a response model, i.e. a model that predicts who will respond to a marketing campaign.
- Should we focus on a particular segment or subgroup? For example, if a marketing campaign wants to focus on people aged 20-30, then modeling this set separately from the set of all people would produce better results.
- What are the relevant business rules? For example, if we are marketing an R-rated movie then we would exclude people under 18 from the model.
- What do they (the business people) know about the data? Domain experts know where data resides and how it is stored. They may know whether some sources are invalid and where certain data should come from.
- What do their intuition and experience say is important? Can be a source of insight.
Checking the opinion of domain experts:
- The data can be used to check that the experience and intuition of domain experts is correct
- Example: If a domain expert believes that the best customer is aged 24 to 31 with at least one university degree, we can check to see if this is supported by the data.
2. Transforming Data into Actionable Results
- The iterative process of building data mining models:
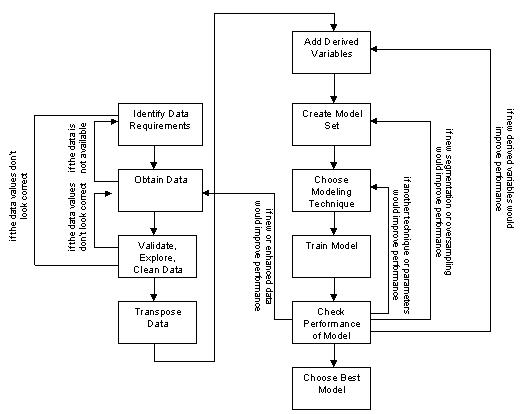
Identify and obtain data
- The right data is often whatever is available, reasonably clean, and accessible
- Data must meet the requirements for solving the business problem
- for example if the business problem is to identify particular customers, then the data must contain information about each individual customer
- Data must be as complete as possible
- When doing predictive modeling the data needs to be complete enough that we can determine the outcome of what we are modeling
Validate, explore and clean the data
- Is there any missing data and will this be a big problem?
- Are the field values within legal bounds?
- Are the field values reasonable?
- Are the distributions of individual fields explainable?
- Data fields which are not used are often inaccurate compared to critical data fields
Transpose the data to the right granularity
- Granularity is the level of the data that is being modeled
- Some data mining algorithms work on individual rows of data, so all data describing a customer must be in a single row
Add derived variables
- Derived variables are calculated based on combinations of other values inside the data
Prepare the model set
- Model set: data used to build the data mining models
- Need to consider such things as the frequency of the rarer outcomes in the model set
- For example, if the frequency of rare outcomes in the model set is too low then the predictions made by the model, although accurate, may never include these rare outcomes
- The model set can be divided into training, test, and evaluation sets
Choose the modeling technique and train the model
- Different data mining tools and algorithms determine the specifics of training a model
Check performance of the models
- Evaluation set (part of the model set) is used to see how well the model performs on unseen data
- Compare results between different models:
- A confusion matrix is used to tell us how many of the model's predictions are correct and how many are incorrect
- Cumulative gains and lift charts are also used to compare models
3. Acting on the Results
- Insights: new facts learned during modeling may lead to insights about the customers and about the business
- One-time results: results may be focused on a particular activity and that activity should be carried out
- Remembered results: information in the results should be accessible through a data mart or a data warehouse
- Periodic predictions: periodically score customers to determine what ongoing marketing efforts should be
- Real-time scoring: model may be incorporated into another system
- Fixing data: may have to fix data problems that have been uncovered
- Experimental design may be added to the process to add valuable insight
- Example: Using an additional random group exposed to a marketing message. This brings in an unbiased sample.
4. Measuring the Model's Effectiveness
- Compare actual results to predicted results
- Actual results are usually worse than predicted because models perform less well the farther they get from the model set
- Over time, actual data will usually be more recent than the model set, so the original patterns become less relevant
What Makes Predictive Modeling Successful?
Time frames of predictive modeling:
- Training: the process of creating a model using historical data and already known instances of what you are trying to predict
- Scoring: the process of applying the model to unseen data to make new predictions, usually from more recent data
Shelf-life of a Model
- Changes over time result in the need to train a new model on more recent data
- Predictions also have a shelf-life because they are valid during a particular time frame (eg. a month)
Key assumptions of predictive modeling:
1. The Past Is a Good Predictor of the Future
- There are some cases where this is not true because it can be hard to capture significant external events in the data
- Example: Housing supply sales go up after a tornado sweeps through town
- Domain experts need to be included in the modeling process because they may have insight into when the past is a good predictor of the future
2. Adequate Data Are Available to Form a Model
- Data used to build the model must also be available to apply the model
- Example: If we gather data in a certain context