


|
Overview of the KDD Process | |
Reference: Fayyad, Piatetsky-Shapiro, Smyth, "From Data Mining to Knowledge Discovery: An Overview", in Fayyad, Piatetsky-Shapiro, Smyth, Uthurusamy, Advances in Knowledge Discovery and Data Mining, AAAI Press / The MIT Press, Menlo Park, CA, 1996, pp.1-34
What is the KDD Process?
The term Knowledge Discovery in Databases, or KDD for short, refers to the broad process of finding knowledge in data, and emphasizes the "high-level" application of particular data mining methods. It is of interest to researchers in machine learning, pattern recognition, databases, statistics, artificial intelligence, knowledge acquisition for expert systems, and data visualization.
The unifying goal of the KDD process is to extract knowledge from data in the context of large databases.
It does this by using data mining methods (algorithms) to extract (identify) what is deemed knowledge, according to the specifications of measures and thresholds, using a database along with any required preprocessing, subsampling, and transformations of that database.An Outline of the Steps of the KDD Process
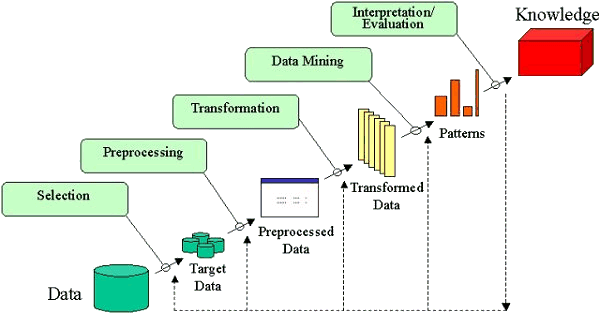
The overall process of finding and interpreting patterns from data involves the repeated application of the following steps:
The terms knowledge discovery and data mining are distinct.
KDD refers to the overall process of discovering useful knowledge from data. It involves the evaluation and possibly interpretation of the patterns to make the decision of what qualifies as knowledge. It also includes the choice of encoding schemes, preprocessing, sampling, and projections of the data prior to the data mining step.
Data mining refers to the application of algorithms for extracting patterns from data without the additional steps of the KDD process.
Definitions Related to the KDD Process
Knowledge discovery in databases is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data.
| Data | A set of facts, F. |
| Pattern | An expression E in a language L describing facts in a subset FE of F. |
| Process | KDD is a multi-step process involving data preparation, pattern searching, knowledge evaluation, and refinement with iteration after modification. |
| Valid | Discovered patterns should be true on new data with some degree of certainty. Generalize to the future (other data). |
| Novel | Patterns must be novel (should not be previously known). |
| Useful | Actionable; patterns should potentially lead to some useful actions. |
| Understandable | The process should lead to human insight. Patterns must be made understandable in order to facilitate a better understanding of the underlying data. |
Interestingness is an overall measure of pattern value, combining validity, novelty, usefulness, and simplicity.
|
|